
En las ultimas entregas, explicamos la estacionalidad, y preprocesamos los datos, ademas empezamos a programar un backtest estacional en python de una forma sencilla. Dejando todo listo para esta nueva entrega.
En esta nueva entrega, una vez tenemos los trades de la operativa que nos devuelve el backtester en un dataframe, vamos a analizarlos. De esta forma podremos ver de un vistazo las estadisticas mas relevantes de la estrategia, ademas, pensando en la siguiente entrega donde programaremos un modulo de busqueda de amplio espectro de estacionalidad intradiaria, el cual el objetivo es que nos devuelva un dataframe con los parametros seleccionados, y las estadisticas mas relevantes.
Otros Articulos de la Serie


Como lo vamos a estructurar
En la siguiente imagen, vemos como acabara nuestra clase. Tenemos ya programadas las funciones que estan dentro del rectangulo rojo, que son las funcionalidades principales para la busqueda de patrones estacionales intradiarios.

El objetivo ahora sera
- Programar los estadisticos mas relevantes como:
- SQN
- VaR & CVaR
- Alpha y Beta
- MDD
- Sharpe Ratio
- Realizar un resumen (summary) donde nos muestra la informacion mas relevante, y que posteriormente utilizaremos para el dataframe resultante de la busqueda de amplio espectro de estacionalidad intradiaria.
Una vez defenidos los objetivos, y explicado que es lo que ya hemos hecho, vamos a ello!
SQN - System Quality Number en Python
Vamos a programar una nueva funcion dentro de nuestra clase, que nos calcule el SQN sobre la curva de nuestra estrategia.
El System Quality Number (SQN), desarrollado por el Dr. Van Tharp, es una métrica estadística diseñada para evaluar la calidad y rendimiento ajustado al riesgo de un sistema de trading.
Fórmula del SQN

Donde:
- Esperanza Matemática (E): Es el promedio del retorno esperado por operación en términos de múltiplos de R (relación beneficio/riesgo).
- Número de Operaciones (N): Total de operaciones realizadas.
- Desviación Estándar (DT): Mide la dispersión o variabilidad de los múltiplos de R.
$$SQN = \sqrt{N} \times \frac{\mathbb{E}[R]}{\sigma_R}$$
Interpretacion del Ratio SQN
Interpretación del SQN
El valor del SQN indica la calidad del sistema:
- < 1.5: Difícil de operar.
- 1.51 - 2.0: Sistema promedio.
- 2.01 - 3.0: Buen sistema.
- 3.01 - 5.0: Excelente sistema.
- 5.01 - 7.0: Sistema sobresaliente.
- > 7.0: "Santo Grial" (extremadamente raro)
Consideraciones Importantes
- Tamaño muestral: Para que el SQN sea estadísticamente significativo, se recomienda un mínimo de 30 operaciones
- Impacto de la desviación estándar: Sistemas con alta variabilidad en los resultados (como estrategias tendenciales) tienden a tener un SQN más bajo debido a su mayor desviación estándar, incluso si son rentables a largo plazo
- Limitaciones: El SQN puede penalizar estrategias con grandes ganancias ocasionales o volatilidad positiva, lo que lo hace más favorable para sistemas con distribuciones consistentes y menores desviaciones
Vamos a crear una nueva funcion dentro de nuestra clase con el siguiente codigo :
def calculate_sqn(self,trades=None):
import numpy as np
if len(trades) == 0:
return 0
avg_trade = trades['Points'].mean()
std_dev = trades['Points'].std()
num_trades = len(trades)
if std_dev == 0:
return 0
sqn = (avg_trade / std_dev) * np.sqrt(num_trades)
return sqn En el codigo lo que hemos realizado es
- Verificar que hay Trades
- Posteriormente calcular los componentes de la formula
- Y calcular el ratio SQN en funcion de los componentes
VaR y CVaR
El VaR y el CVaR son dos estimadores de riesgo,
$$\text{VaR}_\alpha = -\inf\{x : P(L \leq x) \geq \alpha\}$$
$$\text{CVaR}_\alpha = \mathbb{E}[L \mid L \leq \text{VaR}_\alpha]$$

VaR (Value At Risk)
El VaR (Value at Risk) mide la pérdida máxima que una cartera podría experimentar en un período específico, bajo condiciones normales de mercado, con un nivel de confianza determinado. En términos simples, el VaR responde a la pregunta: ¿cuánto puedo perder como máximo en un horizonte temporal dado con una probabilidad específica?
Se podrtia interpretar como si el VaR diario al 95% de una cartera es $1,000,000, significa que hay un 5% de probabilidad de que las pérdidas superen ese monto en un día
Formula
Matemáticamente, el VaR se define como el percentil α de la distribución de pérdidas:

Metodos de Calculo del Value At Risk (VaR)
Existen tres métodos principales para calcular el VaR:
- Simulación histórica: Utiliza datos pasados para estimar posibles pérdidas futuras
- Método de varianza-covarianza: Asume que los retornos tienen una distribución normal
- Simulación Monte Carlo: Genera escenarios aleatorios basados en modelos estadísticos.
Limitaciones
El VaR no considera la magnitud de las pérdidas más allá del umbral definido y puede subestimar el riesgo en eventos extremos (colas gruesas). Por consecuencia, debemos asumir, que el mayor drawdown, o perdida de rendimeinto esta por llegar.
CVaR (Conditional Value At Risk)
El CVaR (Conditional Value at Risk), también conocido como déficit esperado (Expected Shortfall), complementa al VaR al medir la pérdida promedio en los peores escenarios que exceden el umbral del VaR. Por lo tanto, proporciona una visión más completa del riesgo extremo.
Por ejemplo, si el CVaR al 95% es $1,200,000, significa que dentro del 5% de los peores escenarios, las pérdidas promedio serán $1,200,000
Formula
El CVaR se calcula como el promedio de las pérdidas que superan el VaR:

Ventajas
El CVaR tiene mejores propiedades matemáticas que el VaR:
- Es una medida coherente del riesgo (cumple monotonicidad, subaditividad y otras propiedades)
- Captura mejor los riesgos extremos y permite optimizar carteras considerando escenarios adversos
Programacion
Vamos a implementar el Value At Risk, y el Conditional Value at risk en una misma funcion de la siguiente forma:
def calculate_var_cvar(self, confidence_level=0.95):
if not self.trades:
return 0, 0
if isinstance(self.trades, list):
trades_df = pd.DataFrame(self.trades)
else:
trades_df = self.trades
r = trades_df['Points'].values
var = np.percentile(r, (1-confidence_level)*100)
cvar = r[r <= var].mean() if len(r[r <= var]) > 0 else var
return var, cvarPrimero, verificamos que existan trades, posteriormente verificamos que los tenemos en un dataframe, y de no ser asi, lo creamos nosotros.
Asignamos a la variable r los valores de la variacion de nuestra estrategia
Y calculamos el VaR y el CVaR depositando sus resultados en las variables con el mismo nombre y devolviendolas.
El nivel de confianza por defecto es el 95, pero es comun tambien ver gente que lo calcula al nivel del 99%
Calculando las griegas (Alpha y Beta)
Alpha
El Alpha es una métrica que mide el rendimiento adicional o "exceso de retorno" que una inversión genera en comparación con un índice de referencia (benchmark). En otras palabras, refleja cuánto valor agregado (o perdido) aporta un gestor de cartera o estrategia de inversión más allá del comportamiento general del mercado.
- Un Alpha positivo indica que la inversión superó al mercado.
- Un Alpha negativo implica que la inversión tuvo un rendimiento inferior al mercado.
Formula

Interpretacion
- α>0: La inversión generó rendimientos superiores al benchmark ajustados por riesgo.
- α=0: La inversión igualó el rendimiento del benchmark.
- α<0: La inversión tuvo un desempeño inferior al benchmark.
Beta
La Beta es una medida que cuantifica la sensibilidad o volatilidad de un activo en relación con los movimientos del mercado general. Representa el riesgo sistemático, es decir, el riesgo que no puede eliminarse mediante diversificación.
Ejemplos
- Una Beta de 1 indica que el activo se mueve en línea con el mercado.
- Una Beta mayor a 1 implica que el activo es más volátil que el mercado.
- Una Beta menor a 1 sugiere que el activo es menos volátil que el mercado.
Calculo de la Beta

Interpretacion
- β=1: El activo tiene la misma volatilidad que el mercado.
- β>1: El activo es más volátil y arriesgado que el mercado.
- β<1: El activo es menos volátil y, por lo tanto, más defensivo.
- β<0: El activo se mueve en dirección opuesta al mercado.
Codigo en Python
Vamos a programar una funcion, que amplie nuestra clase y nos calcule los valores de la Beta y el Alpha para las estrategias.
def calculate_greeks(self, benchmark_returns=None):
import numpy as np
if not self.trades:
return 0, 0
if isinstance(self.trades, list):
trades_df = pd.DataFrame(self.trades)
else:
trades_df = self.trades
strategy_returns = trades_df['Points'].values
if benchmark_returns is None:
if hasattr(self, 'df') and 'Close' in self.df.columns:
benchmark_returns = self.df['Close'].diff().dropna().values
if len(benchmark_returns) != len(strategy_returns):
benchmark_returns = benchmark_returns[:len(strategy_returns)]
if len(benchmark_returns) != len(strategy_returns):
return 0, 0
if benchmark_returns is None or len(benchmark_returns) != len(strategy_returns):
return 0, 0
if not isinstance(benchmark_returns, np.ndarray):
benchmark_returns = np.array(benchmark_returns)
covariance = np.cov(strategy_returns, benchmark_returns)[0, 1]
variance = np.var(benchmark_returns)
beta = covariance / variance if variance != 0 else 0
avg_strategy = np.mean(strategy_returns)
avg_benchmark = np.mean(benchmark_returns)
alpha = avg_strategy - (beta * avg_benchmark)
return beta, alpha- Si no hay operaciones registradas (
self.tradesestá vacío), devuelve(0, 0)como Beta y Alpha. - Convierte las operaciones (
self.trades) en unDataFramesi es una lista. - Extrae los retornos de la estrategia desde la columna
'Points'. - Si no se proporcionan retornos del benchmark (
benchmark_returns), calcula los retornos basados en los precios de cierre ('Close') del activo original. - Alinea la longitud de los retornos del benchmark con los de la estrategia; si no coinciden, devuelve
(0, 0). - Calcula la Beta
- Si la varianza del benchmark es cero (sin movimientos en el mercado), se establece Beta en
0. - Calcula la Alpha
- Devuelve los valores calculados de Beta y Alpha como una tupla
(beta, alpha).
Max Drawdown (MDD)
El Max Drawdown corresponde a la perdida maxima historica que ha sufrido la estrategia en el pasado. Al estar trabajando con futuros, la calculamos como puntos maximos de perdida, en lugar de porcentajes, y nos sirve para tener una aproximacion de hasta donde llego en el pasado la estrategia hacia una perdida maxima.
Asi que extendemos nuestra clase con los calculos
def calculate_mdd(self, trades=None):
import numpy as np
if trades is None:
if not self.trades:
return 0
trades = pd.DataFrame(self.trades) if isinstance(self.trades, list) else self.trades
if len(trades) == 0:
return 0
equity_curve = trades['Points'].cumsum()
running_max = np.maximum.accumulate(equity_curve)
drawdowns = (equity_curve - running_max)
if np.max(running_max) == 0:
return 0
max_drawdown = np.min(drawdowns)
return abs(max_drawdown)- Si no se proporcionan operaciones (
trades), utiliza las operaciones registradas en la instancia (self.trades). - Convierte las operaciones en un
DataFramesi son una lista. - Si no hay operaciones, devuelve
0como el MDD. - Calcula la curva de equidad acumulando los resultados de las operaciones (
Points) usandocumsum(). - Encuentra los máximos acumulados en la curva de equidad utilizando
np.maximum.accumulate. - Calcula los drawdowns como la diferencia entre la curva de equidad y los máximos acumulados.
- Si el máximo acumulado es cero (por ejemplo, si no hay ganancias ni pérdidas), devuelve
0. - Busca el valor mínimo en los drawdowns (mayor pérdida acumulada).
- Devuelve el valor absoluto del máximo drawdown como resultado (convención positiva).
Ratio de Sharpe
El Ratio de Sharpe, desarrollado por William F. Sharpe, es una métrica financiera que mide la rentabilidad ajustada al riesgo de una inversión. Su objetivo es determinar si los rendimientos de una inversión se deben a decisiones acertadas o simplemente a la asunción de un mayor riesgo. Es ampliamente utilizado para comparar inversiones y evaluar la calidad del rendimiento en relación con el riesgo asumido.
Formula

Donde:
- Rp: Rentabilidad promedio de la inversión o cartera.
- Rf: Rentabilidad del activo libre de riesgo (como bonos del Tesoro).
- σp: Desviación estándar de los rendimientos de la inversión (volatilidad).
Ventajas y Limitaciones
Ventajas
- Permite comparar inversiones con diferentes niveles de riesgo.
- Ajusta los rendimientos en función del riesgo, facilitando análisis más objetivos.
- Es útil para evaluar gestores de carteras o estrategias de trading.
Limitaciones
- Asume que los rendimientos tienen una distribución normal, lo cual no siempre es cierto.
- No distingue entre volatilidad positiva (ganancias) y negativa (pérdidas), lo que puede penalizar estrategias con alta variabilidad positiva.
def calculate_sharpe_ratio(self, trades=None, risk_free_rate=0, periods_per_year=252):
if trades is None:
if not self.trades:
return 0
trades = pd.DataFrame(self.trades) if isinstance(self.trades, list) else self.trades
if len(trades) == 0:
return 0
returns_mean = trades['Points'].mean()
returns_std = trades['Points'].std()
if returns_std == 0:
return 0
sharpe = (returns_mean - risk_free_rate) / returns_std
annualized_sharpe = sharpe * np.sqrt(periods_per_year)
return annualized_sharpeSummary - Crear estadisticas sobre el TradeHistory
Una vez hemos programado todas las funciones de las estadisticas, vamos a programar una funcion que nos haga un 'summary' sobre nuestro tradehistory. Informacion extremadamente util, para cuando lancemos nuestra optimizacion de amplio espectro, poder localizar las zonas horarias con algun tipo de edge, o incluso crear nuestros ratios derivados de los ratios calculados actualmente.
def get_summary(self, benchmark_returns=None, confidence_level=0.95,):
if not self.trades:
return {"message": "No trades found"}
trades_df = pd.DataFrame(self.trades)
winning_trades = trades_df[trades_df['Points'] > 0]
losing_trades = trades_df[trades_df['Points'] < 0]
# Calcular SQN
sqn_value = self.calculate_sqn(trades_df)
# Calcular VaR y CVaR
var, cvar = self.calculate_var_cvar(confidence_level)
# Calcular alpha y beta si hay benchmark
beta, alpha = self.calculate_greeks(benchmark_returns)
# calculate MDD
mdd = self.calculate_mdd(trades_df)
# Calcular Sharpe Ratio
sharpe_ratio = self.calculate_sharpe_ratio(trades_df)
# Calcular el Summary
summary = {
'total_trades': len(trades_df),
'mdd': mdd,
'winning_trades': len(winning_trades),
'losing_trades': len(losing_trades),
'win_rate': len(winning_trades) / len(trades_df) if len(trades_df) > 0 else 0,
'avg_profit': trades_df['Points'].mean(),
'total_profit': trades_df['Points'].sum(),
'max_profit': trades_df['Points'].max(),
'max_loss': trades_df['Points'].min(),
'variance': np.var(trades_df['Points']),
'profit_factor': abs(winning_trades['Points'].sum() / losing_trades['Points'].sum())
if len(losing_trades) > 0 and losing_trades['Points'].sum() != 0 else float('inf'),
'sharpe': sharpe_ratio,
'sqn': sqn_value,
'VaR': var,
'CVaR': cvar,
'beta': beta,
'alpha': alpha
}
return summaryEste código define un método llamado get_summary que genera un resumen estadístico detallado de las operaciones realizadas por una estrategia de trading. Combina varias métricas clave para evaluar el rendimiento, el riesgo y la calidad de la estrategia.
- Si no hay operaciones (
self.tradesestá vacío), devuelve un mensaje indicando que no se encontraron operaciones. - Convierte las operaciones (
self.trades) en unDataFramepara facilitar los cálculos. - Separa las operaciones ganadoras (
winning_trades) y perdedoras (losing_trades) basándose en la columna'Points'. - SQN: Llama al método
calculate_sqnpara calcular el System Quality Number. - VaR y CVaR: Llama al método
calculate_var_cvarpara calcular el Value at Risk y el Conditional Value at Risk con un nivel de confianza especificado. - Alpha y Beta: Llama al método
calculate_greekssi se proporcionan retornos del benchmark. - MDD: Llama al método
calculate_mddpara calcular el Maximum Drawdown. - Sharpe Ratio: Llama al método
calculate_sharpe_ratiopara medir la rentabilidad ajustada al riesgo. - Número total de operaciones, ganadoras y perdedoras.
- Tasa de éxito (win rate): Porcentaje de operaciones ganadoras.
- Promedio, total, máximo beneficio y máxima pérdida.
- Varianza de los resultados.
- Profit Factor: Relación entre las ganancias totales y las pérdidas totales (si hay pérdidas).
- Compila todas las métricas calculadas en un diccionario llamado
summary. - Devuelve el diccionario con todas las estadísticas clave.
Todas las metricas incluidas en el resumen
| Métrica | Descripción |
|---|---|
total_trades |
Número total de operaciones realizadas. |
mdd |
Maximum Drawdown: Mayor pérdida acumulada desde un pico hasta un valle en la curva de equidad. |
winning_trades |
Número de operaciones ganadoras. |
losing_trades |
Número de operaciones perdedoras. |
win_rate |
Porcentaje de operaciones ganadoras sobre el total. |
avg_profit |
Beneficio promedio por operación. |
total_profit |
Beneficio total acumulado. |
max_profit |
Mayor beneficio obtenido en una operación. |
max_loss |
Mayor pérdida sufrida en una operación. |
variance |
Varianza de los resultados (medida de dispersión). |
profit_factor |
Relación entre ganancias totales y pérdidas totales (indicador de eficiencia). |
sharpe |
Ratio de Sharpe: Rentabilidad ajustada al riesgo. |
sqn |
System Quality Number: Calidad del sistema basado en riesgo y rendimiento. |
VaR |
Value at Risk: Pérdida máxima esperada con un nivel de confianza dado. |
CVaR |
Conditional Value at Risk: Pérdida promedio más allá del VaR (riesgo extremo). |
beta |
Sensibilidad del sistema frente a movimientos del mercado (benchmark). |
alpha |
Rendimiento adicional generado por la estrategia ajustado por riesgo sistemático (benchmark). |
Implementacion de lo programado hasta el momento
El primer paso es cargar las librerias, en este caso pandas para cargar el picke de los datos, y nuestro IntradaySeasonalBacktester desde el notebook

Posteriormente, cargaremos a un dataframe nuestro pickle con los datos, en este caso es el futuro del ES preprocesado como explicamos en articulo 1, pero puede ser de cualquier otro activo.
Creamos una instrancia de nuestro IntradaySeasonalBacktester llamada model, le pasamos como argumento el dataframe de nuestros datos preprocesados, y le he metido unos parametros random de dia de la semana de entrada, hora de entrada, minuto de entrada y velas dentro.
Posteriormente ejecutamos el backtest con el metodo run_backtest() para generar el TradeHistory de la estrategia.
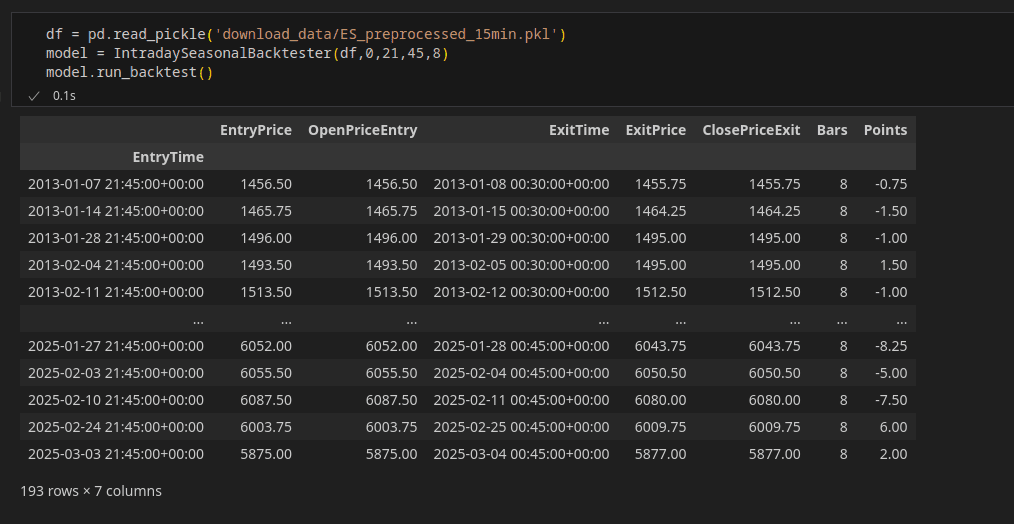
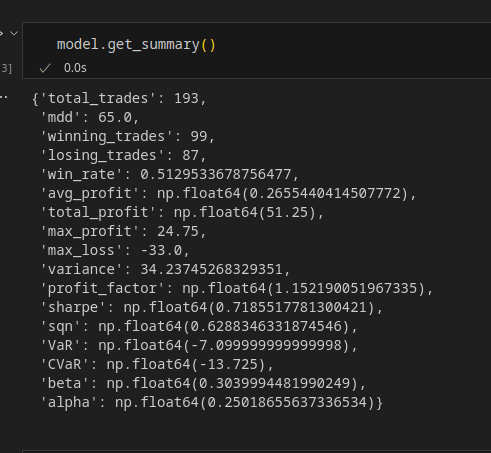
Y ahora vamos a solicitar un summary sobre los trades de la estrategia que acabamos de hacer funcionar, mediante la llamada a la funcion get_summary(), que llamara a todos los estadisticos avanzados que hemos calculado, ademas de otros mas sencillos que calculamos directamente con pandas y numpy. Obteniendo los datos necesarios para una evaluacion de la estrategia.
Enlaces de Interes


Proximamente
En el proximo articulo, vamos a crear un analizador de amplio espectro, que investige todas las franjas horarias del activo, en busca de patrones estacionales intradiarios. Utilizando todos los metodos programados anteriormente y que nos devuelva un dataframe con los parametros utilizados y las estadisticas de dicha combinacion, para posteriormente ejecutar un analisis.
Ante cualquier duda, no dude en contactarme por email a jcx[a]quantarmy.com
Un saludo, Jesus.













{kind=link}