
Introducción al Volatility Targeting
En este estudio, nos proponemos implementar una técnica de Volatility Targeting en Python partiendo de cero. Para ello, haremos uso de una metodología sencilla pero efectiva.
¿Qué son los Objetivos de Volatilidad? (Volatility Targeting)
La historia del volatility targeting se remonta a la década de 1980, cuando los inversores comenzaron a darse cuenta de que la volatilidad era un factor importante en la rentabilidad de las carteras. A medida que los mercados financieros se volvían cada vez más complejos, la necesidad de controlar la volatilidad se hizo más evidente.
En esencia, Volatility Targeting consiste en condicionar la asignación de un activo en función de su nivel de volatilidad. La volatilidad histórica se presenta como una de las métricas más utilizadas en este enfoque. Buscamos gestionar la exposición de la cartera en relación con un objetivo de volatilidad. El target buscado y la volatilidad máxima realizada deben ser similares, de esta forma podremos entender si las técnicas que realizamos son las correctas.
En caso de que la volatilidad aumente, se reducirá la asignación de activos, mientras que si la volatilidad disminuye, se requerirá un mayor apalancamiento. Por defecto, los objetivos de volatilidad se considerarán a nivel anual, a menos que se especifique lo contrario.
$$w_t = \frac{\sigma^*_{\text{target}}}{\sigma_t} \quad \text{where } \sigma^*_{\text{target}} \text{ is the annualized vol target}$$
$$\sigma_{\text{annual}} = \sigma_{\text{daily}} \times \sqrt{252}$$
$$w_t = \frac{\sigma^*_{\text{target}}}{\sigma_t} \quad \text{where } \sigma^*_{\text{target}} \text{ is the annualized vol target}$$
La aplicación de técnicas de Volatility Targeting permite suavizar la volatilidad de la cartera, eliminando una gran parte de la volatilidad presente. Asimismo, podría aumentar la rentabilidad, aunque su principal objetivo es modelar la volatilidad futura de la cartera, más que un aumento en los rendimientos[1][2].
Método de Volatility Targeting Básico

Imaginemos un portfolio con esta composición:
- 60% SPY
- 40% IEF
Por lo general, esta cartera suele clasificarse como de riesgo medio y se considera una de las opciones más utilizadas para fines de benchmarking. Debido a que se trata de una cartera con condiciones fijas, es decir, que no se modifica independientemente de las circunstancias del mercado, resulta altamente vulnerable en periodos de volatilidad.
Aplicando Volatility Targeting
Partimos de un portfolio que puede ser mejorado con facilidad, comenzaremos a programar la base de nuestro estudio. Lo primero será crear la cabecera, que incluirá todas las librerías necesarias y las variables del modelo.
### QUANTARMY 2023 - [jcx@QA]#
### GNU PUBLIC LICENSE CODE
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
import quantstats as qs
qs.extend_pandas()
plt.style.use('dark_background')
st1 = 'SPY'
st2 = 'TLT'
N = 100
data = pd.DataFrame()
Hemos cargado todas las librerías necesarias y asignado las variables st1 y st2 a los dos activos que analizaremos en este estudio. En este caso, hemos elegido utilizar SPY, un ETF que replica de forma eficiente el índice S&P500, y TLT, un ETF que sigue un universo de bonos seleccionados con un plazo de vencimiento superior a los 20 años. Otra opción que se utiliza con frecuencia son los IEF, que tienen un plazo de duración intermedia.
Una vez definida la cabecera, vamos a crear el dataframe principal, y procedemos a descargar toda la información necesaria.
data['s1'] = yf.download(st1)[['Adj Close']].pct_change() * 10
data['s2'] = yf.download(st2)[['Adj Close']].pct_change() * 10
Ahora, es necesario calcular la volatilidad actual y establecer el objetivo de volatilidad que deseamos aplicar en nuestro estudio.
En esta ocasión, fijaremos nuestro objetivo de volatilidad en la volatilidad histórica media del activo desde el inicio de la serie. Para ello, evaluaremos la desviación de la volatilidad del activo en relación con su volatilidad histórica mediante el cálculo de la media móvil de N periodos.
data['v1'] = data['s1'].rolling(N).std().shift(-2)
data['v2'] = data['s2'].rolling(N).std().shift(-2)
data['p1'] = data['v1'] / data['s1'].std().mean()
data['p2'] = data['v2'] / data['s2'].std().mean()
Hemos declarado v1 y v2 como la media móvil de la volatilidad en un periodo anterior de 2 días al actual. La razón de ello es evitar posibles sesgos y filtraciones de información del futuro en nuestro análisis.
Hemos definido las variables p1 y p2 como el cociente entre la volatilidad actual y nuestro objetivo de volatilidad, en este caso, la volatilidad histórica del activo.
Dado que este estimador aumenta junto con la volatilidad móvil, necesitamos crear un nuevo indicador que nos permita ponderar los activos en nuestra cesta de forma adecuada. Este indicador se calculará de la siguiente manera:
Para limitar el apalancamiento y controlar la dirección de nuestro modelo, utilizaremos el indicador 1 - P. Este indicador nos permitirá reducir la exposición del modelo en aquellos activos con mayor volatilidad. Es decir, cuanto mayor sea la volatilidad del activo, menor será su ponderación en nuestra cesta.
data['a_p1'] = 1 - data['p1']
data['a_p1'] = np.where(data['a_p1'] < 0, 0, data['a_p1'])
data['a_p2'] = 1 - data['p2']
data['a_p2'] = np.where(data['a_p2'] < 0, 0, data['a_p2'])
Creando un df tal que:
Analizando los resultados del Volatility Targeting
Una vez hemos creado la matriz con toda la información necesaria para nuestros cálculos, procederemos a visualizar los estimadores P1 para SPY y P2 para TLT en esta ocasión.
data[['p1','p2']].dropna().plot()
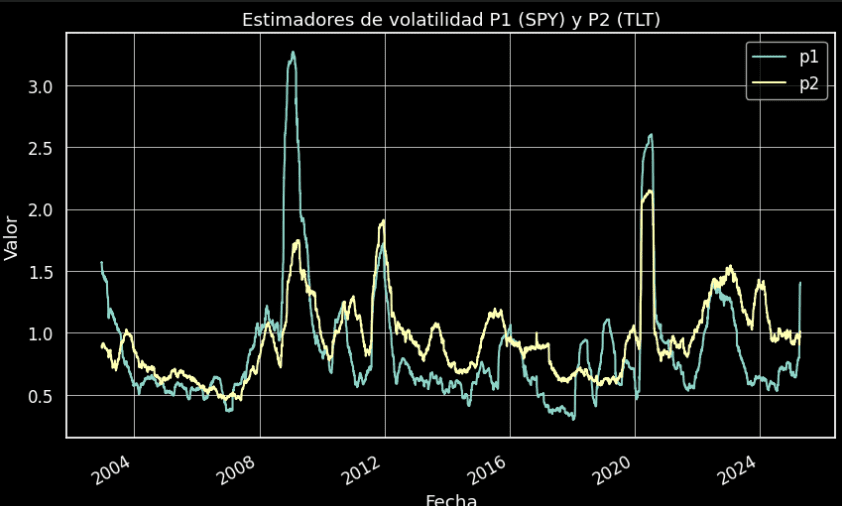
Que la volatilidad del activo SPY es significativamente mayor que la del activo TLT. Sin embargo, se presenta una anomalía en los datos debido a las variaciones de tipos de interés en una economía inflacionaria, donde se observa que la volatilidad realizada en la renta fija del Tesoro Americano es incluso mayor que en el SPY. Se trata de una situación muy particular.
Ahora vamos a analizar cómo serían las ponderaciones de nuestro modelo a lo largo del tiempo.
data[['a_p1','a_p2']].plot()
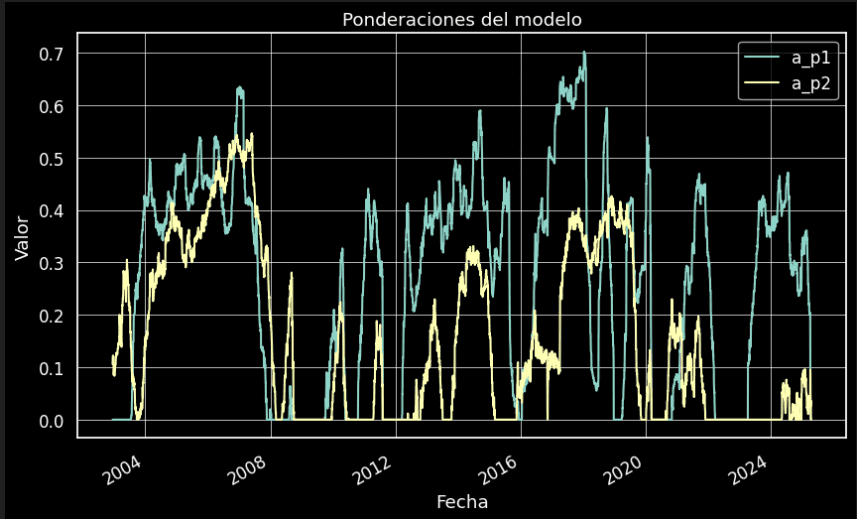
Cómo este método busca reducir la volatilidad del portafolio, centrándose únicamente en períodos de mercado tranquilos. El poder predictivo del modelo es bajo, por lo que no se recomienda utilizarlo para tomar decisiones de inversión a largo plazo. No obstante, la principal ventaja del modelo radica en su capacidad de adaptación al entorno, ya que busca exposición e incluso apalancamiento cuando lo considera apropiado, y puede mantener ponderaciones muy bajas, o incluso salir completamente del mercado, en momentos de alta volatilidad.
Vamos a sumar las dos ponderaciones para analizar si hay momentos en que el modelo está fuera del mercado o está utilizando apalancamiento.
(data['a_p1'] + data['a_p2']).plot()
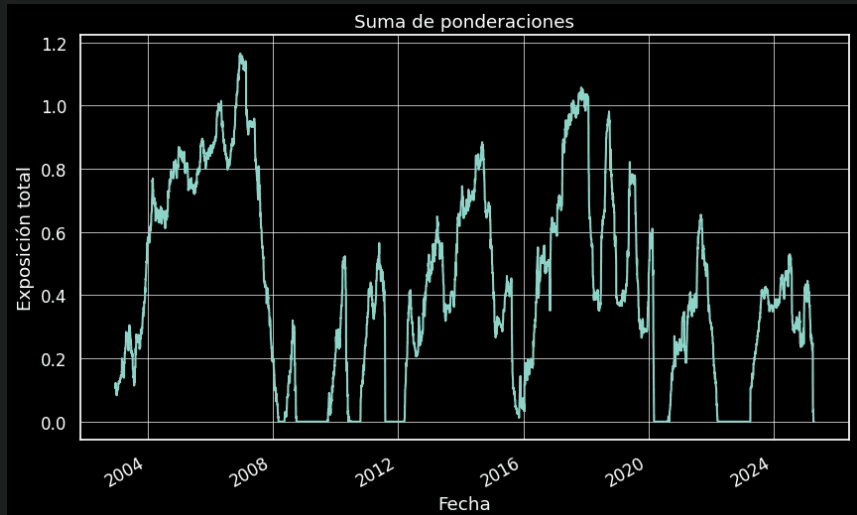
Puede observar en la gráfica, en general el modelo se mantiene por debajo de su nivel máximo sin utilizar apalancamiento, aunque en algunos momentos específicos adopta una estrategia de apalancamiento. Todas las condiciones para un apalancamiento productivo pueden ser definidas en el propio modelo, pero dado el carácter introductorio de este artículo, no se limitará el modelo en este sentido.
Uniendo Retornos con Assets Allocations
Ahora que hemos confirmado que las premisas fundamentales sobre las que se basa este modelo se cumplen, es decir, su capacidad de adaptación a la volatilidad del mercado a través de mecanismos de targeting de volatilidad, podemos pasar al siguiente paso.
Vamos a calcular las curvas de equity para cada activo por separado. Empezaremos con ST1 (SPY).
data['n1'] = data['a_p1'] * data['s1']
Después de aplicar Volatility Targeting, el procedimiento para el cálculo de las curvas de equity es extremadamente sencillo: los retornos porcentuales se multiplican por la ponderación correspondiente. A continuación, presentamos los resultados obtenidos para el activo SPY:
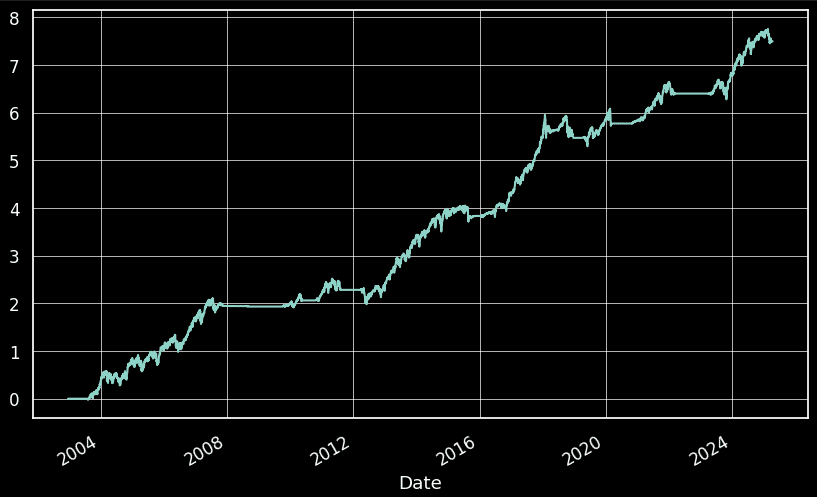
Y para el activo TLT
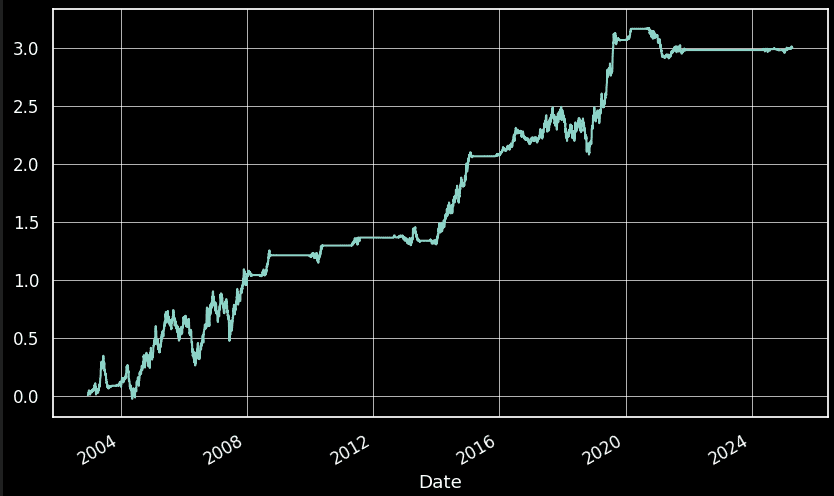
mejor si estos dos activos tienen un comportamiento similar o son diferentes, realizaremos un test de correlación. Se espera encontrar valores que no superen 0.2 o estén por debajo de -0.2. Además, con el Volatility Targeting se ha ajustado la volatilidad de ambos activos.
data[['n1','n2']].corr(method='kendall')
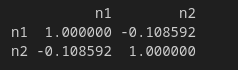
Resultado Final – Volatility Targeting
Para visualizar los resultados de los dos portfolios, simplemente debemos sumarlos. La curva resultante con la aplicación de Volatility Targeting sería la siguiente:
(data['n1'] + data['n2']).cumsum().plot()
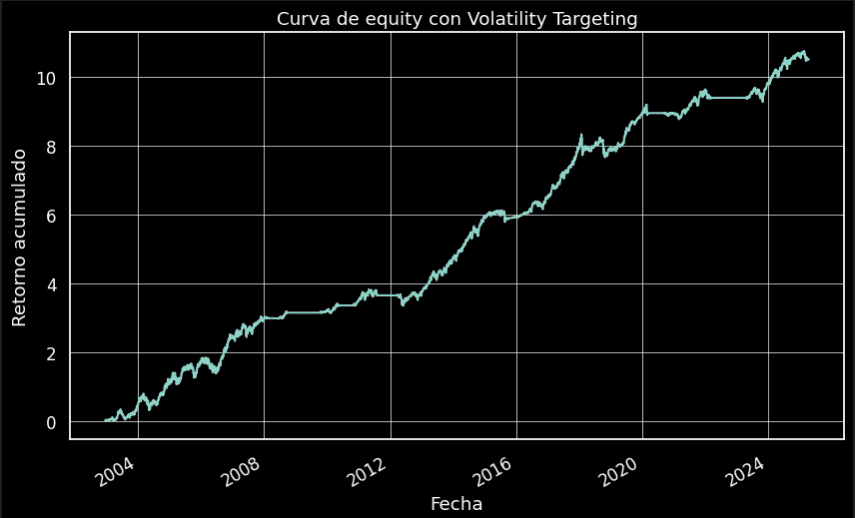
Uno de los gestores de mayor reputación, que ha construido su imperio en base al concepto de volatility targeting ha sido Ray Dalio. Su fondo aplicaba un concepto derivado del volatility targeting. Utilizaba la técnica denominada como Risk Parity.
Recursos:
https://www.ecb.europa.eu/pub/financial-stability/fsr/focus/2020/html/ecb.fsrbox202005_02~f6616db9be.en.html
Si estás buscando entender la volatilidad realizada, te recomendamos que te pases por aquí.
Si estás buscando entender la volatilidad implícita, te recomendamos que te pases por aquí.
Si quieres entender los tres usos más comunes de la volatilidad, te recomendamos que te pases por aquí.
Ampliación para Miembros
La siguiente parte, únicamente para miembros de nuestra army, avanzaremos en el volatility targeting, a nivel activo, y a nivel estrategia. Profundizaremos en los métodos para ajustar nuestro objetivo, que puede ser reutilizado como base para empezar en los métodos de volatility targeting.
Volatility Targeting – A nivel Activo
Dentro del portfolio management, existen tres niveles relevantes de gestión de riesgo de forma esquemática:
- A nivel de Portfolio: Donde el objetivo es controlar la volatilidad de un portafolio multi-strategy, y poder realizar tactical switching.
- A nivel Estrategia: Donde el objetivo es targetear la volatilidad en una única estrategia.
- A nivel Activo: Donde el objetivo está asignado en ajustar la ponderación del asset a la estrategia, de los distintos activos del portfolio.
Aunque existen muchísimas situaciones donde no es posible distinguir entre diferentes niveles de riesgo por la estructura jerárquica de las cestas de riesgo.
Por ejemplo, múltiples estrategias (como diferentes cruces de medias móviles) pueden considerarse como medias o puede ser momentum. Esto puede depender de las preferencias subjetivas del trader, o depender de exposiciones a la estructura de covarianza tanto en formas empíricas como teóricas.
Vamos a programar un bloque que sea utilizable a nivel estrategia, y a nivel assets. Donde targeteamos las volatilidades condicionales como único factor de exposición.
Cuando nos referimos a la exposición, no tenemos una definición acotada de la misma. Considerando la exposición no solo a retornos, sino a cualquier otro factor estimable de la estrategia o activo que estemos analizando, incluso una mezcla de ellas.
Estas serían algunas de los objetivos que deberías controlar la exposición a los portfolio:
- Alpha (Desde el punto de vista del EV)
- Valor Nominal de la exposición
- Exposición al Riesgo como tal













{kind=link}